Introduction
Submission for the Jan 2021 Citi Tech Hackathon. Univest is a two-sided marketplace for Income Share Agreements (ISAs). Students sign up and indicate how much money they need for tuition, then they get offers from investors and choose the best one. Investors submit offers to fund the ISA. They can expect extremely low risk and medium to high returns.
In our MVP students can create a request for an ISA. This is posted to our backend and stored in a SQLite DB. Our machine learning algorithms then go to work calculating the expected yearly ROI over a 10 year timespan after graduation. Investors can search for this ISA requests and see the expected ROI.
Data Analysis

Aim:
To predict investor’s return on investment (ROI).
Strategy:
Use data that can be collected for college students (e.g. major, gender, number of siblings, political views) to train a model that will predict the student’s future income after graduation. Use that prediction to calculate the expected ROI for the investor.
Data:
The data used for the analysis and modelling was collected from General Social Survey (GSS). 10 datasets ranging from the year 2000 to 2018 were combined. Only individuals who fit the target market were kept (individuals within the age range of 21 to 45 who attended college or above). The idea was to see what salaries these individuals were earning and then use back-datable features in the dataset (e.g. gender, parents’ highest level of education) to create a model that can predict salaries using these features. As the features are back-datable we could ask for that information from our student clients and predict their future salary. That prediction is then used to determine the expected ROI.
Breakdown:
EDA, Visualization and Data Wrangling:
A notebook containing the initial analysis of the data:
- Relationship between numerical features and income.
- Distributions of numerical features.
- Correlations (heatmap).
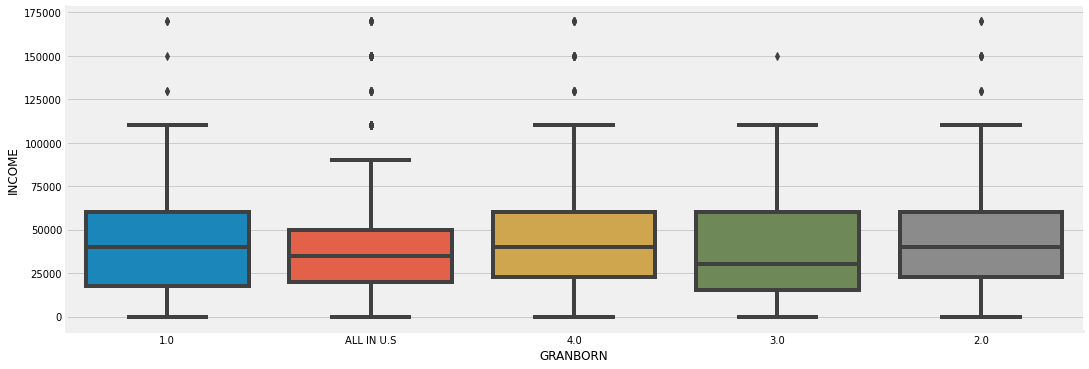
- Relationship between categorical features and income -> our analysis showed that some unexpected datapoints such as the number of grandparents born in the USA correlates strongly with income post-graduation, so when the students sign up for an ISA we ask them this info.
- Feature engineering -> dealing with null values, using predictive models to predict null values.
Modelling, ML Regressors, Keras Feed Forward Neural Network:
- Comparing regression models on a “large” dataset with predicted features.
- Comparing regression models on a “small” dataset without predicted features (dropna).
- Artificial Neural Network
EDA, Visualization and Data Wrangling
Data Overview
| OCC10 | SIBS | AGE | EDUC | PAEDUC | MAEDUC | DEGREE | PADEG | MADEG | MAJOR1 | MAJOR2 | DIPGED | SECTOR | BARATE | SEX | RACE | RES16 | REG16 | FAMILY16 | MAWRKGRW | INCOM16 | BORN | PARBORN | GRANBORN | POLVIEWS | INCOME | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | Broadcast and sound engineering technicians an... | 1.0 | 26.0 | 16.0 | 16.0 | 16.0 | BACHELOR | BACHELOR | GRADUATE | NaN | NaN | NaN | NaN | NaN | MALE | WHITE | CITY GT 250000 | W. SOU. CENTRAL | MOTHER & FATHER | YES | NaN | YES | BOTH IN U.S | 1.0 | SLGHTLY CONSERVATIVE | $8 000 TO 9 999 |
| 1 | Advertising and promotions managers | 6.0 | 44.0 | 14.0 | 12.0 | 12.0 | JUNIOR COLLEGE | HIGH SCHOOL | HIGH SCHOOL | NaN | NaN | NaN | NaN | NaN | FEMALE | WHITE | BIG-CITY SUBURB | E. NOR. CENTRAL | MOTHER & FATHER | YES | NaN | YES | BOTH IN U.S | 1.0 | LIBERAL | $7 000 TO 7 999 |
| 2 | First-line supervisors of office and administr... | 0.0 | 44.0 | 18.0 | 11.0 | 11.0 | GRADUATE | HIGH SCHOOL | HIGH SCHOOL | NaN | NaN | NaN | NaN | NaN | MALE | WHITE | TOWN LT 50000 | W. SOU. CENTRAL | MOTHER & FATHER | YES | NaN | YES | BOTH IN U.S | ALL IN U.S | SLIGHTLY LIBERAL | $50000 TO 59999 |
| 3 | Dispatchers | 8.0 | 40.0 | 16.0 | 10.0 | 10.0 | HIGH SCHOOL | LT HIGH SCHOOL | LT HIGH SCHOOL | NaN | NaN | NaN | NaN | NaN | MALE | BLACK | TOWN LT 50000 | W. SOU. CENTRAL | MOTHER & FATHER | YES | NaN | YES | BOTH IN U.S | ALL IN U.S | MODERATE | $25000 TO 29999 |
| 4 | Software developers, applications and systems ... | 7.0 | 37.0 | 16.0 | NaN | 13.0 | BACHELOR | NaN | HIGH SCHOOL | NaN | NaN | NaN | NaN | NaN | MALE | WHITE | COUNTRY,NONFARM | W. SOU. CENTRAL | MOTHER | YES | NaN | YES | BOTH IN U.S | NaN | LIBERAL | $75000 TO $89999 |
Income Breakdown
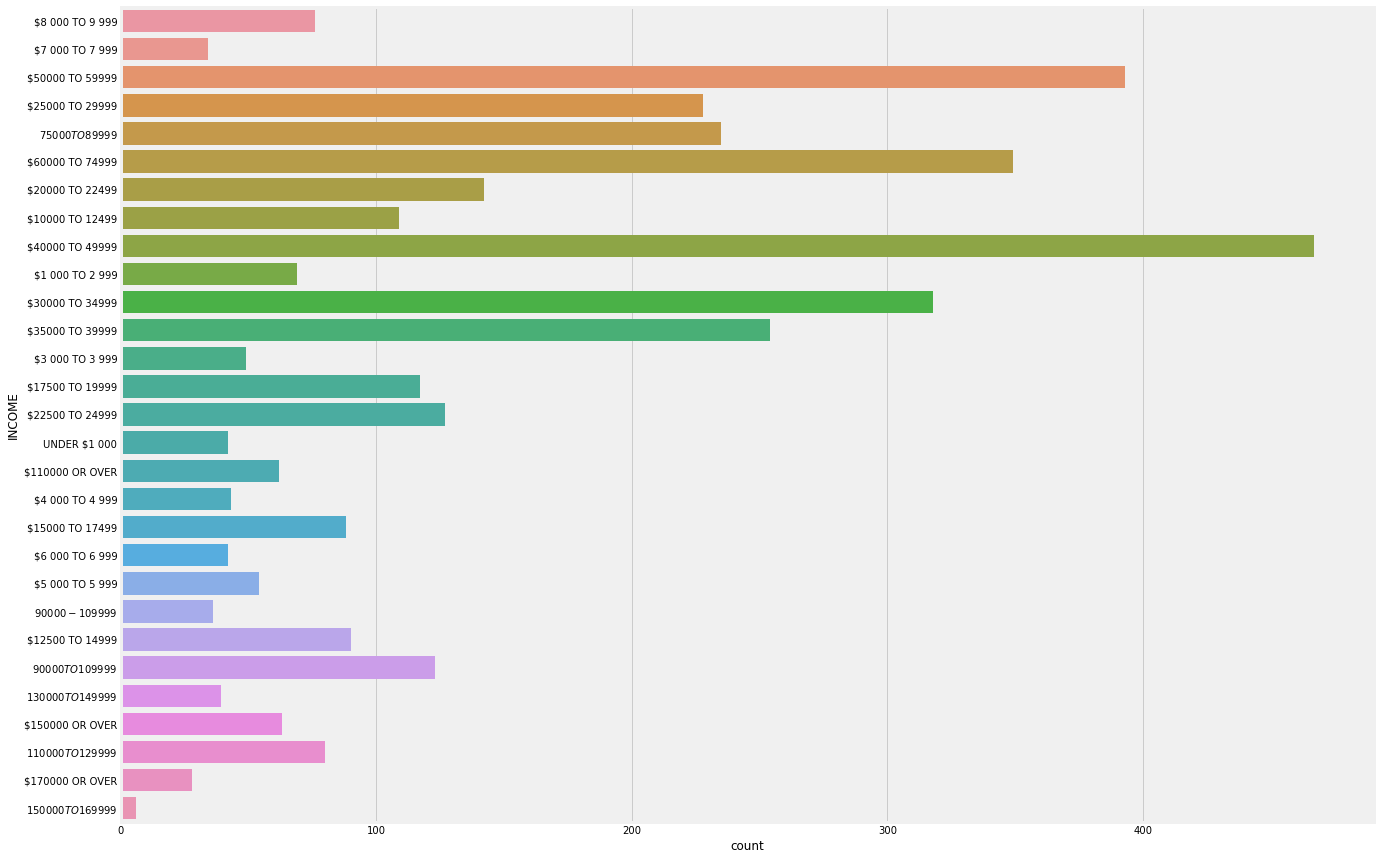
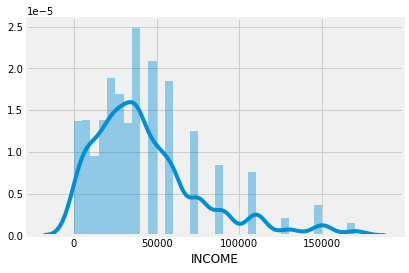
Income is in ranges, we recoded it into numeric variables by taking the lower bound of the range. We took the lower bound instead of the average of a range because some ranges have no upper bound in the data.
After recoding, the income distribution looks as follows:
Income by other features
Corelation Matrixs
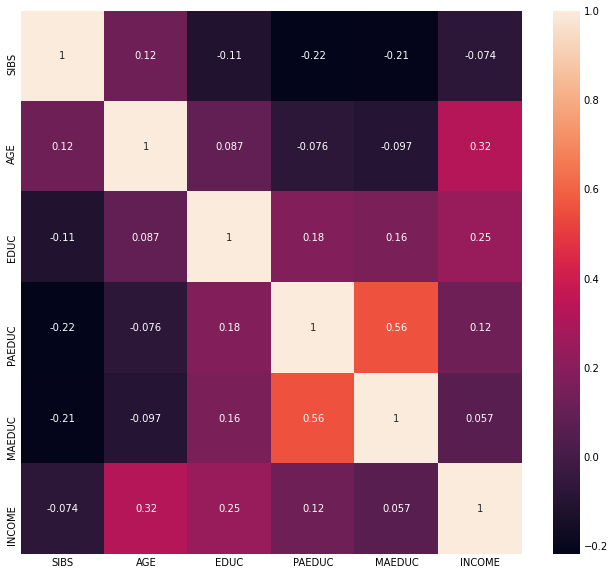
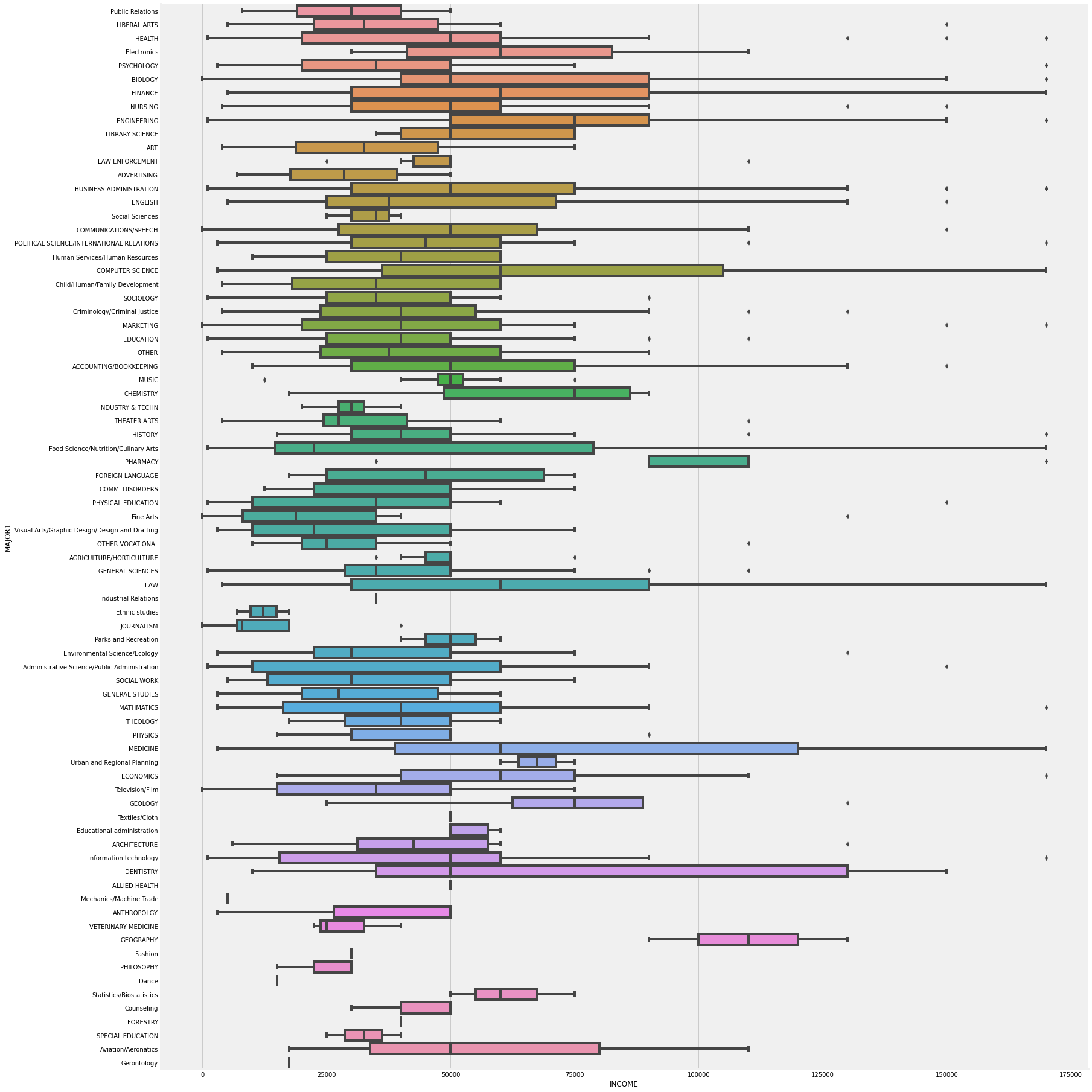
Majors
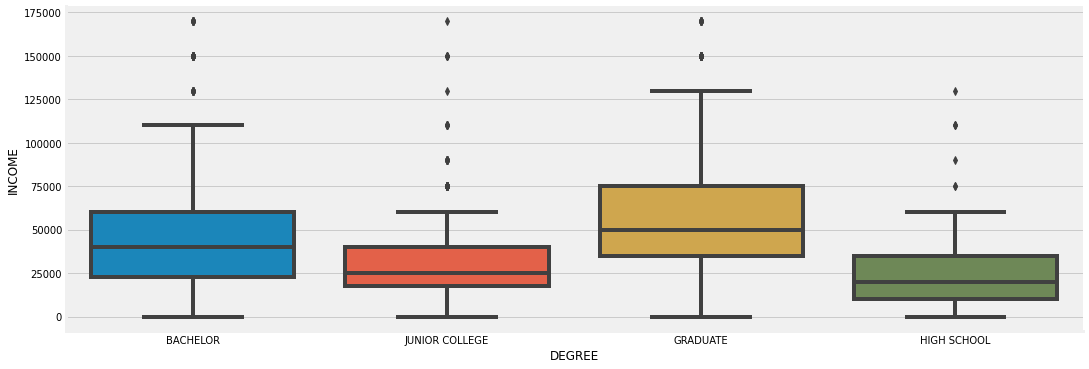
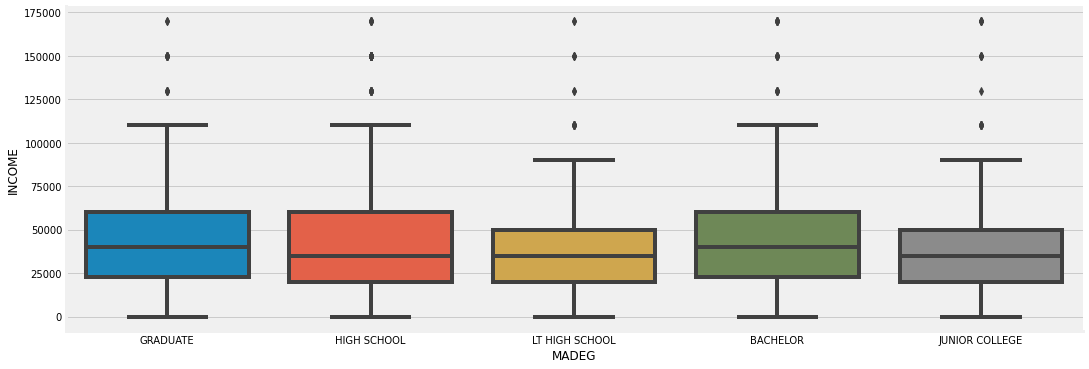
Degrees
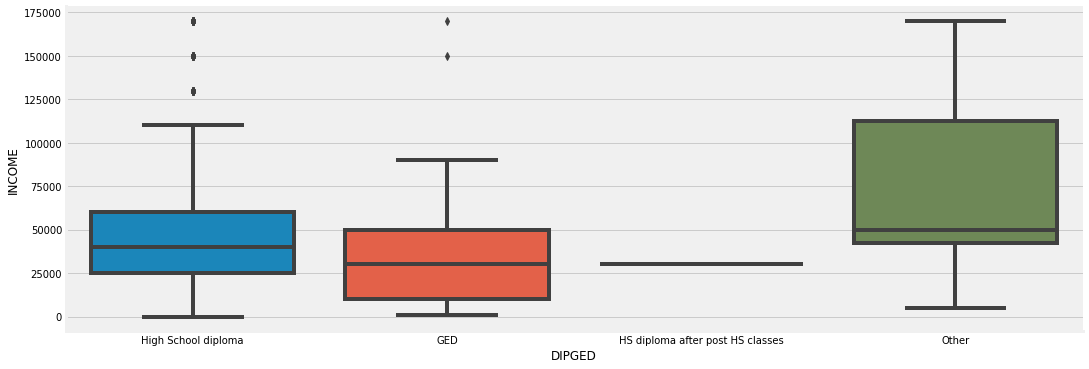
Diplomas
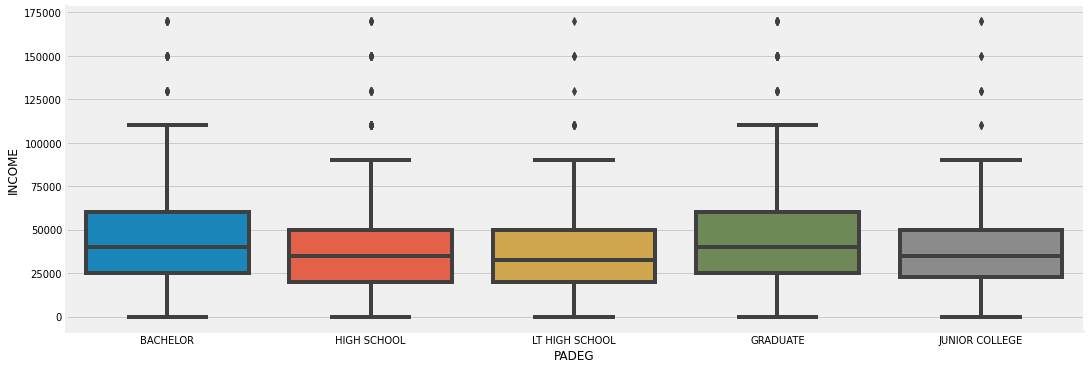
Father’s Education
Mother’s Education
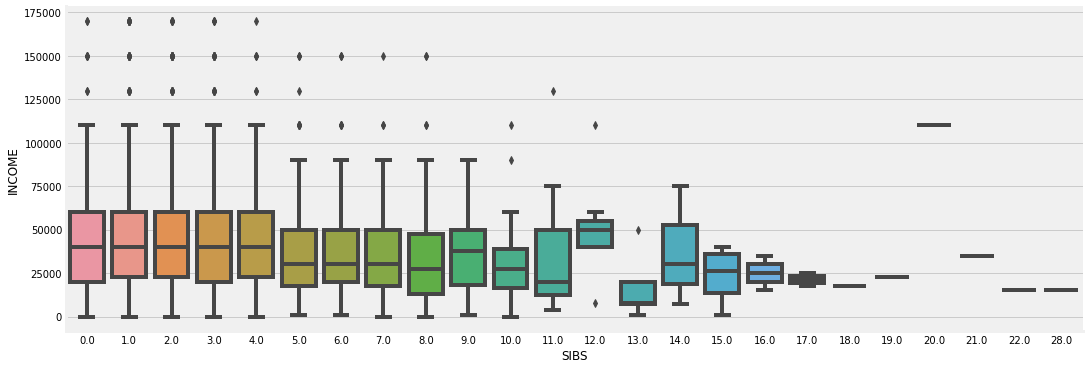
Siblings
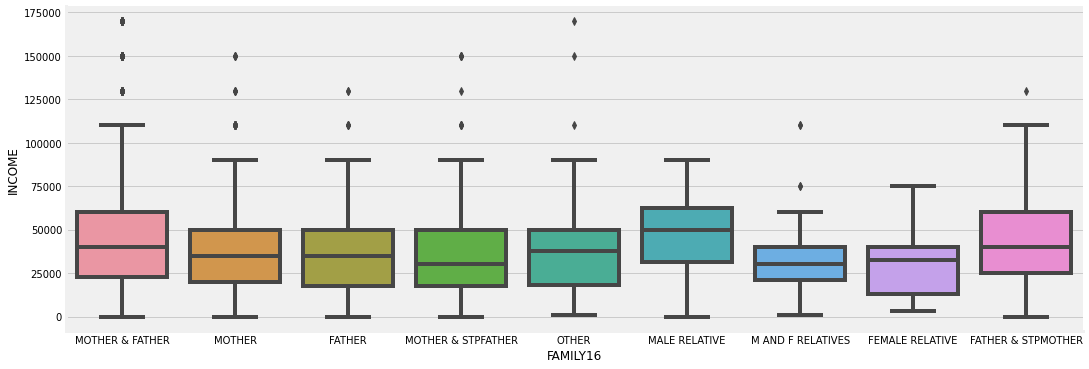
Guardians
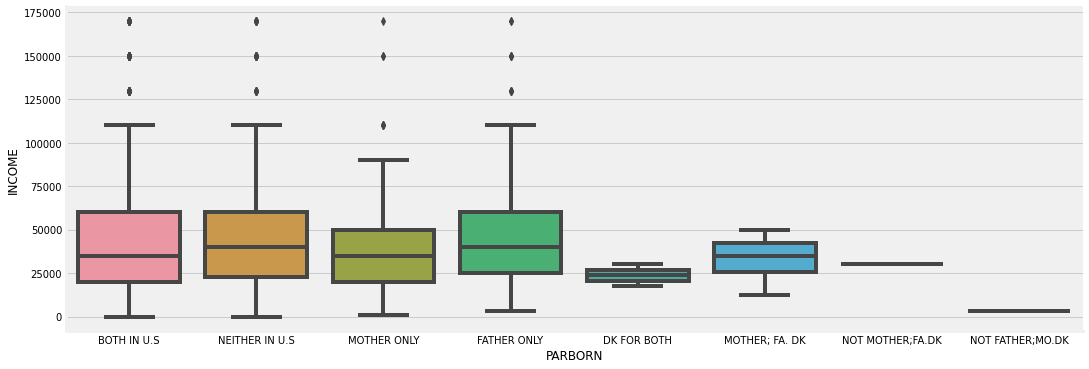
Parents were born in the US
Gradparents were born in the US
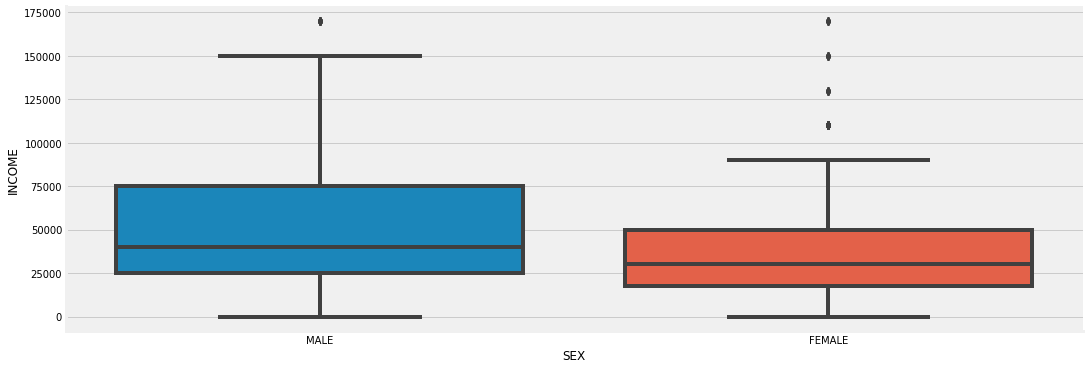
Sex
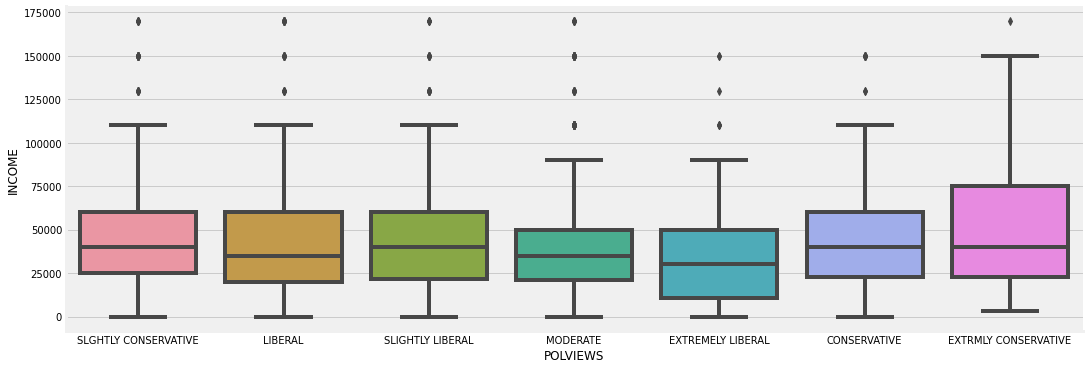
Political Views
Feature Engineering
| Features | No. of Missing |
|---|---|
| MAJOR1 | 2492 |
| DIPGED | 2438 |
| PADEG | 762 |
| POLVIEWS | 465 |
| MADEG | 350 |
| GRANBORN | 301 |
| SIBS | 207 |
| PARBORN | 203 |
| FAMILY16 | 202 |
| DEGREE | 0 |
| SEX | 0 |
Methods:
- Filling the mode for DIPGED, FAMILY16, PARBORN, GRANBORN, MADEG, PADEG.
- Filling the median for SIBS.
- Using SVM, Logistic Regression, Decision Tree, Random Forest models for feature engineering: MAJOR1, POLVIEWS
Polviews
df_dummies_polviews = df.drop(columns = "MAJOR1")
df_dummies_polviews = df_dummies_polviews.dropna()
tmp_y = df_dummies_polviews["POLVIEWS"]
df_dummies_polviews = df_dummies_polviews.drop(columns = "POLVIEWS")
df_dummies_polviews = pd.get_dummies(df_dummies_polviews)
| SIBS | DEGREE_BACHELOR | DEGREE_GRADUATE | DEGREE_HIGH SCHOOL | DEGREE_JUNIOR COLLEGE | PADEG_BACHELOR | PADEG_GRADUATE | PADEG_HIGH SCHOOL | PADEG_JUNIOR COLLEGE | PADEG_LT HIGH SCHOOL | MADEG_BACHELOR | MADEG_GRADUATE | MADEG_HIGH SCHOOL | MADEG_JUNIOR COLLEGE | MADEG_LT HIGH SCHOOL | SEX_FEMALE | SEX_MALE | DIPGED_GED | DIPGED_HS diploma after post HS classes | DIPGED_High School diploma | DIPGED_Other | FAMILY16_FATHER | FAMILY16_FATHER & STPMOTHER | FAMILY16_FEMALE RELATIVE | FAMILY16_M AND F RELATIVES | FAMILY16_MALE RELATIVE | FAMILY16_MOTHER | FAMILY16_MOTHER & FATHER | FAMILY16_MOTHER & STPFATHER | FAMILY16_OTHER | PARBORN_BOTH IN U.S | PARBORN_DK FOR BOTH | PARBORN_FATHER ONLY | PARBORN_MOTHER ONLY | PARBORN_MOTHER; FA. DK | PARBORN_NEITHER IN U.S | PARBORN_NOT FATHER;MO.DK | PARBORN_NOT MOTHER;FA.DK | GRANBORN_1.0 | GRANBORN_2.0 | GRANBORN_3.0 | GRANBORN_4.0 | GRANBORN_ALL IN U.S | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1.0 | 1 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 |
| 1 | 6.0 | 0 | 0 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 |
| 2 | 0.0 | 0 | 1 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 |
| 3 | 8.0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 1 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 |
| 4 | 7.0 | 1 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 |
SVM
model_polviews = svm.SVC(random_state=42)
model_polviews.fit(X_train, y_train)
model_polviews.score(X_test, y_test)
0.2909090909090909
Logistic Regression
model_polviews = LogisticRegression(random_state=42)
model_polviews.fit(X_train, y_train)
model_polviews.score(X_test, y_test)
0.28484848484848485
Decision tree
model_polviews = tree.DecisionTreeClassifier(random_state=42, max_depth=5)
model_polviews.fit(X_train, y_train)
model_polviews.score(X_test, y_test)
0.27575757575757576
Random forest
model_polviews = RandomForestClassifier(max_depth=6, random_state=42)
model_polviews.fit(X_train, y_train)
model_polviews.score(X_test, y_test)
0.2909090909090909
SVM and random forest gave us smiliar results. We use SVM model to predict missing values of political views.
We went through the same process for MAJOR1 and finally used Random Forest to predict missing values of Majors.
Modelling, ML Regressors, Keras Feed Forward Neural Network
Tain test split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
X_train shape: (3010, 128) | X_test shape: (753, 128)</br> y_train mean: 43348.02 | y_test mean: 44745.69</br> 128 features</br>
ML models
Linear Regression
LR = linear_model.LinearRegression().fit(X_train, y_train)
LR.score(X_test, y_test)
-2.7751720305407978e+17
Ridge Regression
RR = linear_model.Ridge(alpha=85, random_state=42).fit(X_train, y_train)
RR.score(X_test, y_test)
0.15757294603748428
Lasso Regression
LAS = linear_model.Lasso(alpha=85, random_state=42).fit(X_train, y_train)
LAS.score(X_test, y_test)
0.15091859140242336
Random Forest
RF = RandomForestRegressor(max_depth=6, random_state=42).fit(X_train, y_train)
RF.score(X_test, y_test)
0.14687449437771827
XGBoost
XG = xgb.XGBRegressor(objective ='reg:squarederror', colsample_bynode = 0.5,colsample_bylevel=0.5, learning_rate = 0.05,
max_depth = 5, alpha = 10, n_estimators = 100, gamma=0.5)
XG.fit(X_train, y_train)
XG.score(X_test, y_test)
0.15566510863040006
Hyperparameter tuning
After a GridSearch for hyperparameters we got the best_params as follows:
best_params={'colsample_bylevel': 0.5, 'colsample_bynode': 0.5, 'colsample_bytree': 0.5, 'gamma': 0, 'learning_rate': 0.05, 'max_depth': 5, 'min_child_weight': 4, 'n_estimators': 100, 'objective': 'reg:squarederror', 'subsample': 0.9}
The XGBoost model is updated:
XG = xgb.XGBRegressor(**best_params)
XG.fit(X_train, y_train)
XG.score(X_test, y_test)
0.16381963132089417
XGBoost gave us the best result so far.
TF/Keras
modelff = Sequential()
modelff.add(Dense(units=512, activation='relu', input_dim=128))
modelff.add(Dropout(0.5))
modelff.add(Dense(units=256, activation='relu'))
modelff.add(Dropout(0.5))
modelff.add(Dense(units=128, activation='linear'))
modelff.add(Dropout(0.5))
modelff.add(Dense(1, activation='linear'))
modelff.compile(loss='mse', optimizer="adam", metrics=['accuracy'])
modelff.summary()
Model: “sequential”:
| Layer (type) | Output Shape | Param # |
| dense (Dense) | (None, 512) | 66048 |
| dropout (Dropout) | (None, 512) | 0 |
| dense_1 (Dense) | (None, 256) | 131328 |
| dropout_1 (Dropout) | (None, 256) | 0 |
| dense_2 (Dense) | (None, 128) | 32896 |
| dropout_2 (Dropout) | (None, 128) | 0 |
| dense_3 (Dense) | (None, 1) | 129 |
| ========== | ||
| Total params: 230,401 | ||
| Trainable params: 230,401 | ||
| Non-trainable params: 0 |